Continuous operations : lessons learned from a simultaneous multiple disk failure issue on a virtualizing RAID computer data storage system – Published 25 July 2019 – ID PM00017 – 10 min read
The Story
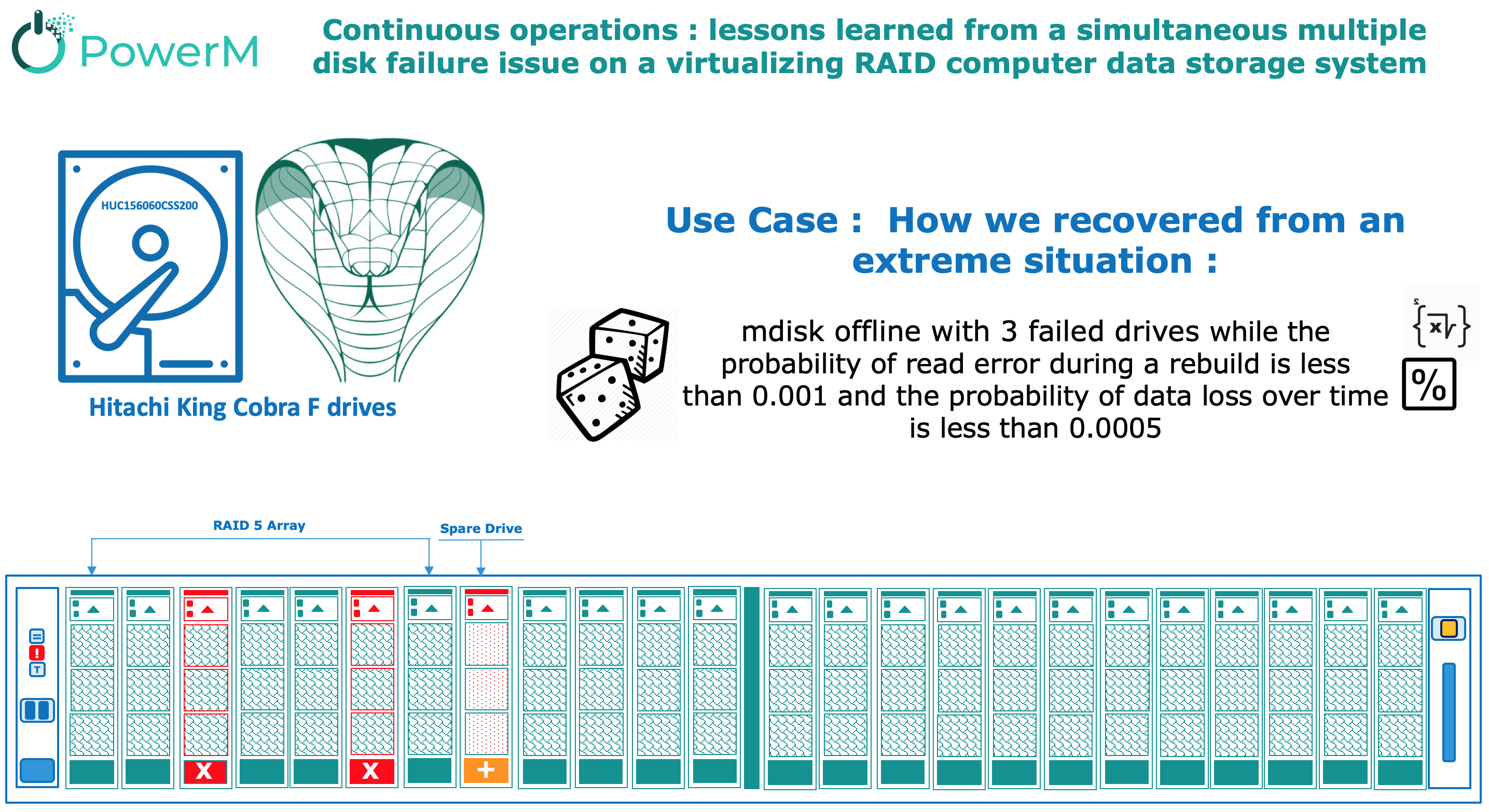
The customer experienced an outage on June 2019 which was triggered by a V7000 GEN2 disk related issue resulting in an offline mdisk : mdisk offline with 3 failed drives with a potential loss of data.
Problem timeline:
- hh:mm the drive ID1 reported a self-test failure and was set to offline due to many reported errors. The RAID-5 Array mdisk0 rebuild started to drive ID2.
- hh:mm+5 the drive ID3 reported multiple hardware failures but stayed online allowing rebuild to drive ID2 to finish. When rebuild to drive ID2 finished,the drive ID3 was set failed due to excessive error and rebuild to drive ID4 started.
- hh+4:mm the drive ID2 went offline during the rebuild of drive ID3 due to too many medium errors thus not allowing the rebuild to drive ID4 to finish and setting array offline.
The disks that failed with “Drive reporting too many medium errors” are related to a particular drive type (HUC156060CSS20 600 GB 15k).
Losing 3 Drives in a RAID5+ Hot Spare configuration looks like a Final Destination movie scene 😀
Overview of Hitachi King Cobra F drives HUC156060CSS200
The Ultrastar C15K600, is the world’s fastest hard disk drive in a 15K RPM, 2.5-inch small form factor hard drive and ideally suited for mission-critical data center and high performance computing environments.
The best-in-class performance is achieved through several innovations, including media caching technology that provides a large caching mechanism for incoming data resulting in significantly enhanced write performance.
The C15K600 is HGST’s first hard drive to leverage an industry-leading 12Gb/s Serial-Attached SCSI (SAS) interface enabling very high transfer rates between host and drive, supporting the performance and reliability needed within the most demanding enterprise computing environments like online transaction processing (OLTP), big data analytics, multi-user applications and data warehousing.
The drive is used on EMC VMAX,EMC VNX, EMC VNX2,HPE 3PAR and IBM Storwize.
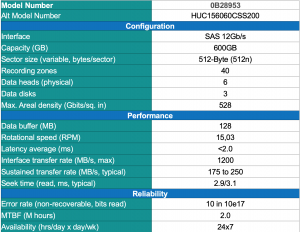
Talking Math: Mean Time To Data Loss (MTTDL)
Mean Time To Data Loss (MTTDL) is one of the standard reliability metric in storage systems. MTTDL represents a simple formula that can be used to compare the reliability of small disk arrays and to perform comparative trending analyses.
In the storage reliability community, the MTTDL is calculated using Continuous-time Markov Chains (a.k.a. Markov model).
The last time I heard about Markov Chains was back in 2001 when i was studying Queueing Network Systems. One of the intriguing course, turns out handy in diagnosing one of the common issues in the storage infrastructure nowadays. It’s not a Math article, so let’s make it simple since we only need to gather two informations : the probability of read error during rebuild and probability of data loss over time.

The odds of read error during rebuild is 0.001055 and the odds of data loss over 5 years is 0.000538 😕 so what really happened ?
IBM Technology Support Services and EMC Technical Advisory knowledge base
Doing some research on the valuable EMC and IBM Support Knowledge base , we find some clue of what potentially make those drives offline:
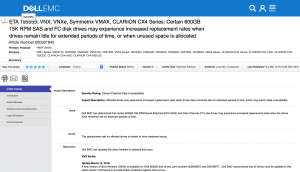
EMC TA 195555: VNX, VNXe, Symmetrix VMAX, CLARiiON CX4 Series: Certain 600GB 15K RPM SAS and FC disk drives may experience increased replacement rates when drives remain idle for extended periods of time, or when unused space is allocated.
Dell EMC has determined that certain 600GB 15K RPM Serial Attached SCSI (SAS) and Fibre Channel (FC) disk drives may experience increased replacement rates when the drives have remained idle for extended periods of time. Affected drives may experience increased replacement rates when drives have remained idle for extended periods of time, which may lead to data unavailability.
IBM notes: on some Hitachi King Cobra F drives used on the IBM Storwize V7000 GEN2, the drives can exhibit either a higher failure rate and/or a very high number of medium errors on many drives and this can result in a higher risk of data loss.A large proportion of Power-On-Idle Hours further aggravates the issue. Indications are that if a drive has experienced a larger number of Power-On-Idle cycles then it will be much more likely to be exposed to this issue. A typical case of error count of a drive occurs when it performs little I/O for long periods and then performs heavy I/O.
Regarding our customers drives , the IBM L3 Support confirm the issue and recommend to upgrade the drives firmware to J2GF after converting the array to RAID6.
Now we have a pretty much clear idea of what would be the root cause analysis of the three drives failures on our V7000, lets see how we were able to recover data.
The recovery process
Hard drive recovery is the process of recovering data and restoring a hard drive to its last known good configuration, after a system/hard drive crashes or is corrupted/damaged.
Recovering data from physically damaged hardware can involve multiple techniques. Some damage can be repaired by replacing parts in the hard disk. This alone may make the disk usable, but there may still be logical damage. A specialized disk-imaging procedure is used to recover every readable bit from the surface. Once this image is acquired and saved on a reliable medium, the image can be safely analyzed for logical damage and will possibly allow much of the original file system to be reconstructed.
Having that said we hired a specialized repair company (Ontrack) to repair Disk ID2. Due to the emergency of the situation, we sent the disk securely on a 3 hours flight to Paris.
48 hours later Ontrack inform us that they were able to copy 99.9% of sectors from the Disk ID2 to a new disk ID5 provided by IBM.
Back to Casablanca Customer Datacenter, we needed to insert the disk ID5 on the V7000 but we had two challenges:
- The V7000 is under IBM SVC.
- We need to manually mark disk ID5 as ID2 so the RAID group would be able to rebuild volumes.
Following an excellent commitment and valuable implication of IBM Systems ,TSS , Support L3 and Development team, IBM provided us with a crafted iFix pre tested in the same conditions as those of PowerM customer (V7000 Gen 2 with Cobra Drives and 7.6 firmware).
- The ifix was installed in service mode, both nodes was put in service mode.
- Executed #satask installsoftware -file <INSTALL_PACKAGE>.
- When both nodes were back up #satask stopservice.
- Once cluster was back online ran #svctask recoverarray 1 and array started rebuilding.
- After some checks on the AIX LPAR box we ran #fsck to check file system consistency : nor file system inode map or block allocation map were corrupted.
- Ran Oracle Database procedure to recover (out of scope of this blog).
10 Lessons learned
Deeply understand Continuous Availability vs HA and DR
High availability (HA) and disaster recovery (DR) are relatively mature approaches that are typically well-known even by non-technical people. Continuous availability is not as mature and can be confused with HA or DR. People still think in terms of “how many 9s” they can achieve (99.999% uptime, for example). But that is an HA topic.
Continuous Availability(CA) = High Availability(HA) + Continuous Operations(CO)

To justify the cost of continuous availability, a measurable impact on the business must be calculated. But often, as soon as the outage is past or if a data center has been fairly stable, the business side forgets the critical need for continuous availability until the next outage occurs.
Read more on https://powerm.ma/always-business-considerations-continuous-availability/
Be realistic about the cost of continuous availability
The cost of implementing continuous availability initiatives can create a high hurdle.
You customers and partners may have unrealistic expectations about implementing continuous availability given the price of hardware. Simply throwing hardware at the problem and building a custom solution is a recipe for high maintenance and unattainable SLAs. The reality is that continuous availability is much more than just hardware and software. The facility prerequisite, the process and resource requirements should be actively taken into consideration.
Challenge the partner and vendor support
ALWAYS ensure that you have a back-to-back support contract with your hardware and middleware providers (IBM,EMC,Redhat,Vmware,Oracle,…).There are always critical incidents that can be only resolved by the L3 and vendors development team.
When you are facing a potential loss of data and you are confident that you’ve correctly designed your infrastructure by respecting all known best practices, don’t accept answers from you partners and vendors like (even they are legitimate) :
- You should restore the last known good backup/ replica.
- You lost two disks in a RAID5 array so you will certainly loose all data in the array.
- You didn’t apply the latest firmware.
- …
There is always a way to recover all or some of the data and you should never give up until you try all possibilities.
Monitor on daily basis
- If a disk fails and you don’t detect it, it’s only a matter of time until its partner will go as well, hence we highly recommend using IBM Spectrum Control as an integrated data and storage management software that will provide you monitoring, automation and analytics for your storage systems including IBM Storwize, SVC and SAN.
- Set up Call Home, Email Alert and Inventory Configuration for your IBM storage.
- Subscribe yourself to IBM ‘My Notification’ for your IBM product.
Mirror everything
You should act like a cloud provider: the data must be available regardless of how important it is or whom is using it ! if they are some inhibitors (cost of replication line , additional storage arrays, datacenter footprint, facilities,…) you should discuss with stockholders and lower the company expectations.
Backup everything
With next-gen data backup and disaster recovery (reduction algorithms, compression , deduplication ,space efficiency , copy data management ,…) we highly recommend to backup not only the production but also every single VM, file systems or databases accessible by some users even occasionally, you only need to adjust your data protection policy and use world-class solutions like IBM Spectrum Protect, Protect Plus, EMC DataDomain,…
Consider a global tech refresh every 5 to 6 years
The technology is moving very fast.You should consider a tech refresh every five to six year. Here is a simple case of the evolution of IBM SVC over the last fifteen years:

Upgrade to the latest recommended Firmware
Be sure that you have at least N-2 version of firmware applied to you storage systems, for instance your IBM Storwize V7000 (2076) should be at 8.1 level. Review the firmware recommendation at least every 3 month.
Use RAID6/DRAID over RAID5
When choosing a RAID type, it is imperative to think about its impact on disk performance and application IOPS.
In a RAID 5 implementation, a write operation might manifest as four I/O operations. When performing I/Os to a disk configured with RAID 5, the controller must scan, calculate, and write a parity segment for every data write operation.
In RAID 6, which maintains dual parity, a disk write requires three read operations: two parity and one data. After calculating both the new parities, the controller performs three write operations: two parity and an I/O. Therefore, in a RAID 6 implementation, the controller performs six I/O operations for every write I/O, and therefore the write penalty is 6.

How can we mitigate the RAID6 write penalty?
- With the advanced cache-based capabilities on the IBM Storwize V7000 and IBM SVC , the write-penalty associated with additional parity will not impact application performance: the write response time is hidden from the hosts by the write cache.
- If you are using massive replication from a V7000 to another system consider using additional CPU.
- When using large drives, consider implementing Distributed RAID :
- Faster drive rebuild improves availability and enables use of lower cost larger drives with confidence
- All drives are active, which improves performance especially with flash drives
- No “idle” spare drives
Choose the right partner
Choose Power Maroc 😎
References
- IBM Reliability of Data Storage Systems -Zurich Research Laboratory – Keynote NexComm 2015
- Hard Disk Drive Specification Ultrastar C15K600 2.5” SAS Hard Disk Drive
- Mean time to meaningless: MTTDL, Markov models, and storage system reliability
- Redbook Implementing the IBM Storwize V7000 Gen2 – ISBN-10: 0738440264- SG24-8244-00
- Always On: Business Considerations for Continuous Availability IBM REDP5090
- EMC Technical Note TA 195555
- Critical Capabilities for Solid-State Arrays Published 6 August 2018 – ID G00338538
Disclaimer
This content was provided for informational purposes only. The opinions and insights discussed are mine and do not necessarily represent those of the Power Maroc S.A.R.L.
Nothing contained in this article is intended to, nor shall have the effect of, creating any warranties or representations from Power Maroc S.A.R.L or its Partners (particularly IBM and DELL Technologies), or altering the terms and conditions of any agreement you have with Power Maroc S.A.R.L.